Compreender o poder da aprendizagem ao longo da vida através do Algoritmo Eficiente de Aprendizagem ao Longo da Vida (ELLA) e do VOYAGER

Encorajo você a ler a Parte 1: As Origens do LLML, caso ainda não o tenha feito, onde vimos o uso do LLML no aprendizado por reforço. Agora que cobrimos a origem do LLML, podemos aplicá-lo a outras áreas, especificamente ao aprendizado multitarefa supervisionado, para ver um pouco do verdadeiro poder do LLML.
LLML supervisionado: o algoritmo eficiente de aprendizagem ao longo da vida
O Algoritmo Eficiente de Aprendizagem ao Longo da Vida visa treinar um modelo que se destaque em múltiplas tarefas ao mesmo tempo. ELLA opera no ambiente de aprendizagem supervisionada multitarefa, com múltiplas tarefas T_1..T_n, com recursos X_1..X_n e y_1…y_n correspondentes a cada tarefa (cujas dimensões provavelmente variam entre as tarefas). Nosso objetivo é aprender as funções f_1,.., f_n onde f_1: X_1 -> y_1. Essencialmente, cada tarefa possui uma função que recebe como entrada os recursos correspondentes da tarefa e gera seus valores y.
A um nível elevado, o ELLA mantém uma base partilhada de vectores de “conhecimento” para todas as tarefas e, à medida que novas tarefas são encontradas, o ELLA utiliza o conhecimento da base refinado com os dados da nova tarefa. Além disso, ao aprender esta nova tarefa, mais informações são adicionadas à base, melhorando o aprendizado para todas as tarefas futuras!
Ruvolo e Eaton usaram ELLA em três ambientes: detecção de minas terrestres, reconhecimento de expressões faciais e previsões de notas em exames! Como uma pequena amostra para deixá-lo entusiasmado com o poder do ELLA, ele alcançou um algoritmo até 1.000 vezes mais eficiente em termos de tempo nesses conjuntos de dados, sacrificando quase nenhum recurso de desempenho!
Agora, vamos mergulhar nos detalhes técnicos do ELLA! A primeira questão que pode surgir ao tentar derivar tal algoritmo é
Como exatamente encontramos quais informações em nossa base de conhecimento são relevantes para cada tarefa?
ELLA faz isso modificando nossas funções f para cada t. Em vez de ser uma função f(x) = y, agora temos f(x, θ_t) = y onde θ_t é exclusivo da tarefa t e pode ser representado por uma combinação linear dos vetores da base de conhecimento. Com este sistema, agora temos todas as tarefas mapeadas no mesmo dimensão básica e pode medir a similaridade usando distância linear simples!
Agora, como derivamos θ_t para cada tarefa?
Esta questão é o insight central do algoritmo ELLA, então vamos dar uma olhada detalhada nela. Representamos os vetores de base de conhecimento como matriz L. Dados os vetores de peso s_t, representamos cada θ_t como Ls_t, a combinação linear de vetores de base.
Nosso objetivo é minimizar a perda de cada tarefa e, ao mesmo tempo, maximizar as informações compartilhadas usadas entre as tarefas. Fazemos isso com a função objetivo e_T que estamos tentando minimizar:
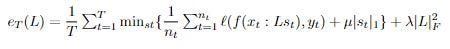
Onde ℓ é a nossa função de perda escolhida.
Essencialmente, a primeira cláusula explica a nossa perda específica da tarefa, a segunda tenta minimizar os nossos vetores de peso e torná-los esparsos, e a nossa última cláusula tenta minimizar os nossos vetores de base.
**Esta equação carrega duas ineficiências (veja se você consegue descobrir quais)! A primeira é que nossa equação depende de todos os dados de treinamento anteriores (especificamente a soma interna), o que podemos imaginar ser incrivelmente complicado. Aliviamos esta primeira ineficiência usando uma soma de Taylor de aproximação da equação. Nossa segunda ineficiência é que precisamos recalcular cada s_t para avaliar uma instância de L. Eliminamos essa ineficiência removendo nossa minimização sobre z e, em vez disso, computando s quando t foi interagido pela última vez. Encorajo você a ler o artigo original para uma explicação mais detalhada!**
Agora que temos nossa função objetivo, queremos criar um método para otimizá-la!
No treinamento, trataremos cada iteração como uma unidade onde recebemos um lote de dados de treinamento de uma única tarefa, depois calculamos s_t e, finalmente, atualizamos L. No início do nosso algoritmo, definimos T (nosso número- contador de tarefas), A, b e L para zeros. Agora, para cada lote de dados, calculamos com base nos dados de uma tarefa vista ou não.
Se encontrarmos dados de uma nova tarefa, adicionaremos 1 a T e inicializaremos X_t e y_t para esta nova tarefa, definindo-os iguais ao nosso lote atual de X e y.
Se encontrarmos dados que já vimos, nosso processo fica mais complexo. Adicionamos novamente nossos novos X e y para adicionar nossos novos X e y à nossa memória atual de X_t e y_t (analisando todos os dados, teremos um conjunto completo de X e y para cada tarefa!). Também atualizamos gradativamente nossos valores A e b negativamente (explicarei isso mais tarde, lembre-se disso por enquanto!).
Agora verificamos se queremos encerrar nosso ciclo de treinamento. Definimos nosso (θ_t, D_t) igual à saída de nosso aluno regular para nossos dados em lote.
Em seguida, verificamos o encerramento do loop (se vimos todos os dados de treinamento). Se ainda não terminamos, passamos para a computação s e a atualização de L.
Para calcular s, primeiro calculamos o modelo ideal \theta_t usando apenas os dados em lote, que dependerão de nossa tarefa específica e função de perda.
Em seguida, calculamos D_t e, aleatoriamente ou para um dos θ_ts, inicializamos quaisquer colunas totalmente zero de L (o que ocorre se um determinado vetor de base não for utilizado). Na regressão linear,

e na regressão logística

Então, calculamos s_t usando L resolvendo um problema de regressão regularizado por L1:

Para nossa etapa final de atualização de L, tomamos

descubra onde o gradiente é 0 e, em seguida, resolva L. Ao fazer isso, aumentamos a dispersão de L! Em seguida, produzimos a vetorização colunar atualizada de L como

para não somar todas as tarefas para calcular A e b, nós as construímos incrementalmente à medida que cada tarefa chega.
Depois de iterar todos os dados em lote, aprendemos todas as tarefas corretamente e terminamos!
O poder do ELLA reside em muitas de suas otimizações de eficiência, principalmente em seu método de usar funções θ para entender exatamente qual conhecimento básico é útil! Se você deseja uma compreensão mais aprofundada do ELLA, recomendo fortemente que você verifique o pseudocódigo e a explicação no artigo original.
Usando o ELLA como base, podemos imaginar a criação de uma IA generalizável, que pode aprender qualquer tarefa que lhe seja apresentada. Temos novamente a propriedade de que quanto mais cresce a nossa base de conhecimento, mais ‘informações relevantes’ ela contém, o que aumentará ainda mais a velocidade de aprendizagem de novas tarefas! Parece que ELLA poderia ser o núcleo de um dos alunos artificiais superinteligentes do futuro!
Viajante
O que acontece quando integramos o mais novo salto em IA, LLMs, com Lifelong ML? Conseguimos algo que pode vencer o Minecraft (este é o cenário do papel real)!
Guanzhi Wang, Yuqi Xie e outros viram a nova oportunidade oferecida pelo poder do GPT-4 e decidiram combiná-la com ideias do aprendizado ao longo da vida que você aprendeu até agora para criar a Voyager.
Quando se trata de aprender jogos, algoritmos típicos recebem objetivos finais predefinidos e pontos de verificação para os quais eles existem apenas para serem perseguidos. Em jogos de mundo aberto como o Minecraft, entretanto, há muitos objetivos possíveis a serem perseguidos e uma quantidade infinita de espaço para explorar. E se nosso objetivo for aproximar a automotivação humana combinada com maior eficiência de tempo nos benchmarks tradicionais do Minecraft, como conseguir um diamante? Especificamente, digamos que queremos que nosso agente seja capaz de decidir sobre tarefas viáveis e interessantes, aprender e lembrar habilidades e continuar a explorar e buscar novos objetivos de uma forma “automotivada”.
Para atingir esses objetivos, Wang, Xie e outros criaram a Voyager, que chamaram de o primeiro agente de aprendizagem ao longo da vida incorporado com tecnologia LLM!
Como funciona a Voyager?
Em grande escala, a Voyager usa o GPT-4 como sua principal ‘função de inteligência’ e o próprio modelo pode ser separado em três partes:
- Currículo automático: Isto decide quais objetivos perseguir e pode ser considerado o “motivador” do modelo. Implementado com o GPT-4, eles o instruíram a otimizar objetivos difíceis, porém viáveis, e a “descobrir tantas coisas diversas quanto possível” (leia o artigo original para ver as instruções exatas). Se passarmos quatro rodadas do nosso loop do mecanismo de prompt iterativo sem que o ambiente do agente mude, simplesmente escolhemos uma nova tarefa!
- Biblioteca de habilidades: uma coleção de ações executáveis, como craftStoneSword() ou getWool(), que aumentam em dificuldade à medida que o aluno explora. Esta biblioteca de habilidades é representada como um banco de dados de vetores, onde as chaves incorporam vetores de descrições de habilidades geradas pelo GPT-3.5 e habilidades executáveis em forma de código. O GPT-4 gerou o código das habilidades, otimizado para generalização e refinado pelo feedback do uso da habilidade no ambiente do agente!
- Mecanismo de prompt iterativo: Este é o elemento que interage com o ambiente do Minecraft. Primeiro ele executa a interface do Minecraft para obter informações sobre seu ambiente atual, por exemplo, os itens em seu inventário e as criaturas ao redor que pode observar. Em seguida, ele solicita o GPT-4 e executa as ações especificadas na saída, oferecendo também feedback sobre se as ações especificadas são impossíveis. Isto se repete até que a tarefa atual (conforme decidido pelo currículo automático) seja concluída. Ao concluir, adicionamos a habilidade aprendida à biblioteca de habilidades. Por exemplo, se nossa tarefa era criar uma espada de pedra, agora colocamos a habilidade craftStoneSword() em nossa biblioteca de habilidades. Por fim, pedimos ao currículo automático uma nova meta.
Agora, onde é que a Aprendizagem ao Longo da Vida se enquadra em tudo isto?
Quando encontramos uma nova tarefa, consultamos nosso banco de dados de habilidades para encontrar as 5 habilidades mais relevantes para a tarefa em questão (por exemplo, habilidades relevantes para a tarefa getDiamonds() seriam craftIronPickaxe() e findCave().
Assim, utilizámos tarefas anteriores para aprender a nossa nova tarefa de forma mais eficiente: a essência da aprendizagem ao longo da vida! Através deste método, a Voyager explora e cresce continuamente, aprendendo novas competências que aumentam a sua fronteira de possibilidades, aumentando a escala de ambição dos seus objetivos, aumentando assim os poderes das suas competências recém-aprendidas, continuamente!
Em comparação com outros modelos como AutoGPT, ReAct e Reflexion, a Voyager descobriu 3,3x mais itens novos que esses outros, navegou distâncias 2,3x mais longas, desbloqueou o nível de madeira 15,3x mais rápido por iteração imediata e foi o único a desbloquear o nível de diamante da árvore tecnológica! Além disso, após o treinamento, quando lançada em um ambiente completamente novo, sem itens, a Voyager resolveu consistentemente tarefas inéditas, enquanto outras não conseguiram resolver nenhuma em 50 solicitações.
Como demonstração da importância da Aprendizagem ao Longo da Vida, sem a biblioteca de competências, o progresso do modelo na aprendizagem de novas tarefas estabilizou após 125 iterações, enquanto que com a biblioteca de competências, continuou a aumentar ao mesmo ritmo elevado!
Agora imagine esse agente aplicado ao mundo real! Imagine um aluno com tempo infinito e motivação infinita que poderia continuar aumentando sua fronteira de possibilidades, aprendendo cada vez mais rápido quanto mais conhecimento prévio tiver! Espero já ter ilustrado adequadamente o poder do Lifelong Machine Learning e sua capacidade de desencadear a próxima transformação da IA!
Se você estiver mais interessado no LLML, encorajo você a ler o livro de Zhiyuan Chen e Bing Liu, que descreve os possíveis caminhos futuros que o LLML pode seguir!
Obrigado por chegar até aqui! Se você estiver interessado, confira meu site anandmaj.com, que contém meus outros escritos, projetos e arte, e siga-me no Twitter @almondgod.
Artigos originais e outras fontes:
Eaton e Ruvolo: Algoritmo Eficiente de Aprendizagem ao Longo da Vida
Wang, Xie, et al: Viajando
Chen e Liu, Lifelong Machine Learning (me inspirou a escrever isso!): https://www.cs.uic.edu/~liub/lifelong-machine-learning-draft.pdf
LL não supervisionado com currículos: https://par.nsf.gov/servlets/purl/10310051
LL profundo: https://towardsdatascience.com/deep-lifelong-learning-drawing-inspiration-from-the-human-brain-c4518a2f4fb9
IA neuro-inspirada: https://www.cell.com/neuron/pdf/S0896-6273(17)30509-3.pdf
LL incorporado: https://lis.csail.mit.edu/empowered-lifelong-learning-for-decision-making/
LL para classificação de sentimento: https://arxiv.org/abs/1801.02808
Aprendizagem vitalícia de robôs: https://www.sciencedirect.com/science/article/abs/pii/092188909500004Y
Ideia de base de conhecimento: https://arxiv.org/ftp/arxiv/papers/1206/1206.6417.pdf
Q-Learning: https://link.springer.com/article/10.1007/BF00992698
AGI LLLM LLMs: https://towardsdatascience.com/towards-agi-llms-and-foundational-models-roles-in-the-lifelong-learning-revolution-f8e56c17fa66
DEPS: https://arxiv.org/pdf/2302.01560.pdf
Voyager: https://arxiv.org/pdf/2305.16291.pdf
Meta-aprendizagem: https://machine-learning-made-simple.medium.com/meta-learning-why-its-a-big-deal-it-s-future-for-foundation-models-and-how- para melhorar-c70b8be2931b
Pesquisa de aprendizagem por meta-reforço: https://arxiv.org/abs/2301.08028



{kind=link}